


Regex: Checking rows with a specific pattern
- sam33frodon
- Dec 28, 2020
- 1 min read
Updated: Jan 27, 2021
library(readr)
library(tidyverse)
library(purrr)adult <- read_csv("adultincome.csv")## Parsed with column specification:
## cols(
## age = col_double(),
## workclass = col_character(),
## fnlwgt = col_double(),
## education = col_character(),
## education.num = col_double(),
## marital.status = col_character(),
## occupation = col_character(),
## relationship = col_character(),
## race = col_character(),
## sex = col_character(),
## capital.gain = col_double(),
## capital.loss = col_double(),
## hours.per.week = col_double(),
## native.country = col_character(),
## income = col_character()
## )We are looking for the total number of rows containing the patter ‘?’
missing_count_tbl <- purrr::map_df(adult, ~ stringr::str_detect(., pattern = "\\?")) %>%
rowSums() %>%
tbl_df() %>%
filter(value > 0) %>%
summarize(missing_count = n())
missing_count_tbl## # A tibble: 1 x 1
## missing_count
## <int>
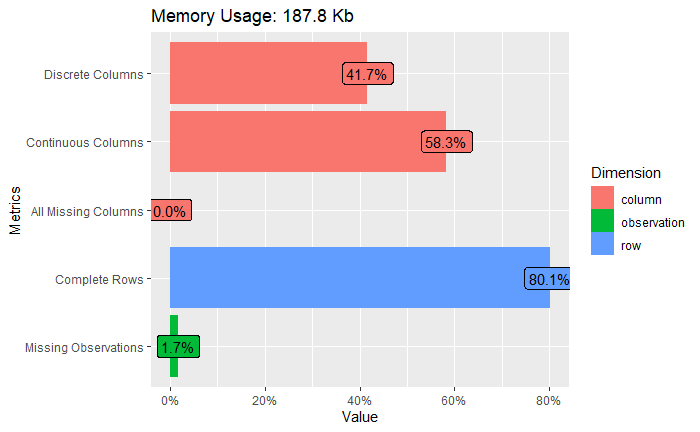
## 1 2399In the data, there are 2399 rows that contain the pattern “?”.
To locate columns that have this pattern
count.NA.percolumn <- plyr::ldply(adult, function(c) sum(c == "?"))
count.NA.percolumn## .id V1
## 1 age 0
## 2 workclass 1836
## 3 fnlwgt 0
## 4 education 0
## 5 education.num 0
## 6 marital.status 0
## 7 occupation 1843
## 8 relationship 0
## 9 race 0
## 10 sex 0
## 11 capital.gain 0
## 12 capital.loss 0
## 13 hours.per.week 0
## 14 native.country 583
## 15 income 0There are 3 columns that contain “?” as NA: workclass, occupation, and native.country.
Comments