


Devise an effective telemarketing strategy to sell long-term deposit accounts to consumers
- sam33frodon
- Jan 20, 2021
- 8 min read
Updated: Jan 25, 2021
Summary
It is of vital importance to target the right customer to ensure the success of the financial institution. If the contacted customer does not subscribe to the product offered; the outbound calls would be a monumental waste of effort and time while the inbound calls with extensive contact would be considered obtrusive and annoying. The main focus should be directed towards the task of selecting the best set of clients I.e., those who are more likely to subscribe to the product. We have employed several methods to resample unbalanced data. The SMOTE (Synthetic Minority Over-Sampling Technique) appears to be the best practice to resample the data whereas Decision Trees, Naïve Bayes and Random Forest portray equally satisfactory performances with regards to customer classification based on accuracies. Optimal performance was achieved by employing Random Forest, yielding the highest accuracy of 94.3%. In order to manage an effective and efficient telemarketing campaign, the financial institution may target retirees, students and people with no personal or housing loans. The number of contact calls should be less than five and the best chance to close the deal may happen in March, September, November or December.
1. Data preparation and exploratory data analysis (EDA)
The data consisted of 4521 customers through direct marketing campaigns (phone calls) from a Portuguese banking institution. The data contains 17 attributes and the description of each attribute is shown in Table 1. The data also contains 7 numeric attributes, including age, balance, day, duration, campaign, pdays, and previous. The dataset contains 10 categorical attributes with 6 multi-valued categorical attributes (job, marital, education, contact, month, and poutcome) and 3 yes/no binary attributes (default, housing, and loan). The target attribute y indicates whether the client has subscribed to a term deposit or not (binary: "yes","no"). The data does not contain any missing values.

The statistical analysis was performed using Tableau Software. The numbers are given in Table 1A (See Appendix). For the numeric attributes, the values of statistics (min, max, mean, 1st quantile, 3st quantile, median, standard deviation) are reported. Skewness and outliers are found in the numerical independent variables. Also, the class attribute is unbalanced, with only about 11% customers subscribed and about 89% did not subscribe. In order to examine the presence of outliers, we plotted all the numeric attributes by using the box-plot feature in Tableau (Figure 1). We divided each attribute into two classes (yes and no), according to the class attributes to identify patterns that can predict whether a customer will or will not subscribe.



Figure 1 clearly exhibits that all numeric attributes have outliers. The figure 1(a) shows the distribution of customers’ age and identifies that those customers who subscribed to the product have higher age seniority. The figure 1d indicates that the longer the duration of the last call; the higher the probability of closing the sale. The correlation between numeric attributes in the data set is shown in Figure 2. There is no correlation between these variables, except for pdays and previous, displaying the correlation coefficient of about 0.6, which we derived by using Python.

By plotting campaign (the number of calls performed during the marketing campaign and for this customer) and duration (Figure 3), we see that a client is more likely to subscribe for the term deposit if the customer speaks for a longer length of time; though the number of calls should be less than 5.

Table 2 summarizes the percentage of class attribute in function of three attributes: loan, housing, and default. The likelihood of future customers to subscribe may no depend on whether they have credit card in default or not. People with no personal loan and housing loan will possibly be interested in the banking products.

In order to examine the influence of attributes with more categories on the class attribute, we used stacked bar charts and pie charts to compare the percentage of customers who did and did not subscribe. All the categorical attributes were examined (Figure 4-9).






These charts depict the probability of the future client subscribing; and from these charts, we gathered some preliminary observations. Education and marital status do not seem to have a strong impact. The characteristics of people who tend to subscribe are as follows:
· People with no personal loan and housing loan
· Cellular and telephone as contact mode (we speculate unknown mode is email)
· The previous outcome (poutcome) has a distinct impact; people who subscribed to the last campaign tend to subscribe again (63.34%)
· Retired people and students
· Contact months: March, September, October, and December.
2. Classification
In this project, three machine learning methods are used to perform classification. Preprocessing the data for each of the three algorithms were performed using SMOTE and randomization. In this project, we used the following parameters to evaluate models: accuracy, precision, recall, and F-score.
2.1. Dealing with unbalanced data
The data is really dominated by the class ‘No’. Only 521 instances correspond to the class Yes, whereas 4000 correspond to the class No. Standard classifier algorithms like Decision Trees are biased towards the majority classes. They tend to only predict the majority of data in the class. The features of the minority class are treated as noise and are often ignored. Thus, there is a high probability of misclassification of the minority class when compared to the majority class. By running classification tree (J48) on the raw data, we obtained a high accuracy of 98% (Table 3). However, the precision and recall for class Yes are only 0.533 and 0.355, respectively. This result clearly shows that accuracy is not an appropriate measure to evaluate model performance when working with unbalanced data.

In order to avoid misclassification, we performed resampling of our data, by using 3 features available in WEKA, including classbalancer, subspreadsample, and SMOTE (Synthetic Minority Over-sampling Technique). The Class Balancer simply reweights the instances so that the sum of weights for all classes of instances in the data are the same. No instances were deleted or added, so the count for each class remains unchanged. The premise behind ClassBalancer is reweighting the instances in each class to obtain a same total class weight. This filter changes only the weight of the first batch of the data. The classBalancer feature is used with the Filtered Classifier feature. In contrast, SpreadSubsample modifies the instance weights so that the "total weight per class is maintained" (i.e., is the same as in the original dataset). This method will randomly under-sample the majority class (No in our data), and reduce the number of instances to be equal with the minority class. In consequence, 512 instances of class NO will be randomly selected from the initial 4000 instances. The data is therefore balanced. Weka has the feature for applying SMOTE (Synthetic Minority Over-sampling Technique) to balance the dataset. By using SMOTE, we increased the number of instances of minority class (YES). The number of nearest neighbours was set at 5. The percentage was set at 668, i.e. the number of instances the YES class will increase 6.68 time in order to balance with the NO class. The number of instances in minority class (YES) increased to 4001. The data is therefore balanced. It should be noted that as a result of SMOTE creating more than 3000 instances for the class YES, the results viewed in the CSV file were not randomly distributed. All the instances added were found in the class YES at the bottom of the table. Therefore, before we applied J48, we also used the randomize feature in the Filter Option so that when we used 10-fold cross-validation, the instances were randomly distributed. The result is shown in Table 4.

2.2. Data splitting
In order to determine the right way to split data, we examined two methods: repeated hold-out and 10-fold cross validation. For the repeated hold-out, the data was split: 90% (for training) and 10% (for testing). The random seed for Xval varies from 1 to 10. The random seed for Xval is the seed of the random number generator used in the heuristics. It is important when looking at a model using cross-validation or percentage split, to validate the model several times before changing this seed. The accuracies of repeated hold-out and 10-fold cross validation are 91.40 ± 0.09 % and 91.10 ± 1.23 %, respectively (See Table A2 in Appendix), demonstrating that the repeated hold gave the accuracy with increased variance (Figure 10).

2.2. Optimizing J48
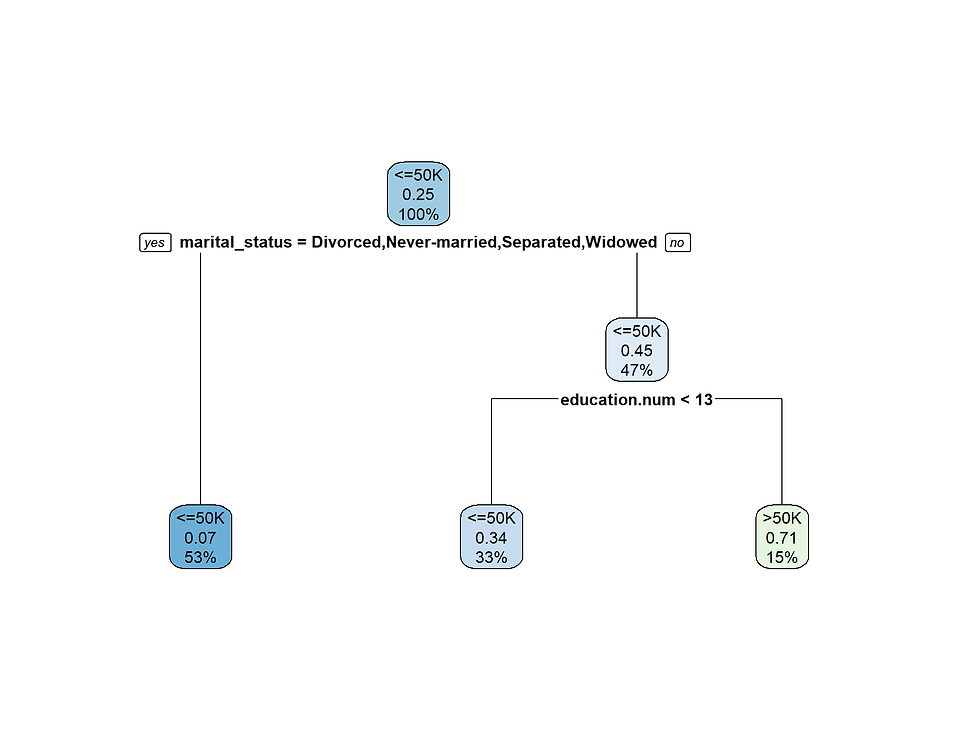
In order to optimize the decision tree, we chose two variables: confidenceFactor(c) and minnumobj (m). The confidenceFactor represents the confidence factor used for pruning (smaller values incur more pruning). The minnumobj represents the minimum number of instances per leaf. All the metrics to evaluate our models are reported in Table 3A (See Appendix). The accuracy varies from 87% to 91%. Figure 11 shows a left side of the full tree. The root of the tree starts at duration, confirming that duration is the most important feature. This is in accordance with the value of the information gain found in section 2.3. If duration is smaller or equal to 210, then the next feature in the tree is housing, so on and so forth.

2.2. Naïve Bayes Classifier
Naïve Bayes classifier is a probability-based classifier for a classification machine learning problem. It is based on Bayes theorem with an assumption of independence between variables. The response variable to be predicted here is classed as “Yes” and “No” and the fundamental nature of predictors appear to be relatively independent of each other. Another advantage of Naïve Bayes Classifier is that the probability of a prediction can be calculated with relative ease. Also, a diagnostic analysis of the model is performed before any conclusions are contemplated. Naïve Bayes classifier does not offer many options for varying the default settings in Weka. The one parameter that resulted in a significant improvement was setting “useSupervisedDiscretization” to yes.

The bank marketing dataset has a large population, and for that reason we decided to model our data using the random forest algorithm. Random forest has the advantage that it combines multiple decision trees into a single model, and when combined together the prediction yields higher accuracy. The result of the Random forest classifier is reported in Table 6.
2.3. Random forest
The bank marketing dataset has a large population, and for that reason we decided to model our data using the random forest algorithm. Random forest has the advantage that it combines multiple decision trees into a single model, and when combined together the prediction yields higher accuracy. The result of the Random forest classifier is reported in Table 6.

The key parameter for random forest is the number of attributes. In Weka, this can be controlled by the numFeatures attribute, which by default is set to 0. We varied the numFeatures from 0 to 10 and no significant changes were observed.
2.3. Performance Comparison of the Algorithms
Table 7 compares the performance of the three classification algorithms. We obtained the best performance with random forest, showing the highest accuracy and F-measure.

As previously exhibited the three models we have built each have their own accuracy in predicting whether a client will say “yes” or “no” to a term deposit in the bank. However, there are some variations in the misclassification error rates among the three classifiers. Based on the performance measure, the most reliable model for the data set was determined to be the Random Forest model, exhibiting the highest accuracy.
3. Conclusion
Implementing machine learning techniques, we were able to evaluate the data provided to develop a greater understanding of the banking dataset. Among the three classification approaches used to model the data, the random forest algorithm yielded the greatest accuracy with just 6% misclassification error rate. An additional advantage is the simplicity of the model, making it easy to implement.
The following features can help the bank to target client.
· WHO: Student, retired, no credit card in default, no personal loan
· WHEN: March, September, October, December
· HOW: cellular, the number of calls should be less than 5
· AND: unknown, success previous outcome

Comments